Create a SharePoint Connector
A SharePoint connector enables you to ingest data from your SharePoint instance (and OneDrive) into the Zeta Alpha platform. This guide shows you how to create and configure a SharePoint connector for your data ingestion workflows, including options that impact crawling performance.
Info: This guide presents an example configuration for a SharePoint connector. For a complete set of configuration options, see the SharePoint Connector Configuration Reference.
Prerequisites
Before you begin, ensure you have:
- Access to the Zeta Alpha Platform UI
- A tenant created
- An index created
- SharePoint credentials (refer to the PDF tutorial "Setup Zeta Alpha SSO with Azure AD.pdf" for detailed instructions)
Step 1: Create the SharePoint Basic Configuration
To create a SharePoint connector, define a configuration file with the following basic fields:
is_document_owner: (boolean) Indicates whether this connector "owns" the crawled documents. When set totrue, other connectors cannot crawl the same documents.schedule: (string, optional) The schedule to crawl the SharePoint instance (cron format).content_source_name: (string) The name that identifies the content source in the index.access_credentials: (object) The credentials required to access SharePoint:client_id: The client ID of your SharePoint applicationclient_secret: The client secret of your SharePoint applicationtenant_id: The tenant ID of your SharePoint application
logo_url: (string, optional) The URL of a logo to display on document cards when no image is extracted from the pipeline.
Example Configuration
Here is an example of a basic SharePoint connector configuration:
{
"name": "my_sharepoint_connector",
"description": "My SharePoint connector for product data",
"is_indexable": true,
"connector": "sharepoint",
"connector_configuration": {
"is_document_owner": true,
"content_source_name": "SharePoint Files",
"access_credentials": {
"client_id": "my_client_id",
"client_secret": "my_client_secret",
"tenant_id": "my_tenant_id"
},
"logo_url": "https://mycompany.com/logo.png"
}
}
Step 2: Add Field Mapping Configuration
When crawling SharePoint, the connector extracts document metadata and content as described in the SharePoint Connector Configuration Reference. You can map these SharePoint fields to your index fields using the field_mappings configuration.
Example Field Mappings
The following example shows field mappings for the default index fields:
{
...
"connector_configuration": {
...
"field_mappings": [
{
"content_source_field_name": "name",
"index_field_name": "DCMI.title"
},
{
"content_source_field_name": "last_modified_date_time",
"index_field_name": "DCMI.modified"
},
{
"content_source_field_name": "created_date_time",
"index_field_name": "DCMI.created"
},
{
"content_source_field_name": "author",
"index_field_name": "DCMI.creator",
"inner_field_mappings": [
{
"content_source_field_name": "display_name",
"index_field_name": "full_name"
},
{
"content_source_field_name": "display_name",
"index_field_name": "Ontology_ID"
}
]
},
{
"content_source_field_name": "content_source_name",
"index_field_name": "DCMI.source"
}
],
...
}
}
Step 3: Specify What to Crawl
You can configure the SharePoint connector to crawl specific content from your SharePoint instance. While a full crawl is possible, we recommend specifying what to crawl to avoid unnecessary data and improve performance.
Available Configuration Options
include_one_drives: (boolean, optional) Whether to include OneDrives in the crawl.one_drive_users: (array of strings, optional) If OneDrives are included, specify the email addresses of users whose drives should be crawled.drive_inclusion_regex_patterns: (array of strings, optional) Regular expressions to match specific drives to crawl.drive_exclusion_regex_patterns: (array of strings, optional) Regular expressions to exclude specific drives from the crawl.site_paths: (array of objects, optional) Specific sites to crawl. If not specified, the connector crawls all sites. Each object contains:collection_hostname: The hostname of the SharePoint instancesite_relative_path: The relative path of the site to crawl
include_sub_sites: (boolean, optional) If nosite_pathsspecified, whether to include sub-sites in the crawl.site_inclusion_regex_patterns: (array of strings, optional) Regular expressions to match specific sites to crawl.site_exclusion_regex_patterns: (array of strings, optional) Regular expressions to exclude specific sites from the crawl.path_inclusion_regex_patterns: (array of strings, optional) Regular expressions to match specific file paths to crawl.path_exclusion_regex_patterns: (array of strings, optional) Regular expressions to exclude specific file paths from the crawl.
Example Configurations
Example 1: Crawl all information in the SharePoint instance
{
"name": "my_sharepoint_connector",
"description": "My SharePoint connector for product data",
"is_indexable": true,
"connector": "sharepoint",
"connector_configuration": {
"is_document_owner": true,
"content_source_name": "SharePoint Files",
"access_credentials": {
"client_id": "my_client_id",
"client_secret": "my_client_secret",
"tenant_id": "my_tenant_id"
},
"logo_url": "https://mycompany.com/logo.png",
"include_one_drives": true,
"one_drive_users": [
"zeta@zeta-alpha.com",
"alpha@zeta-alpha.com"
],
"field_mappings": [
...
]
}
}
Example 2: Crawl only specific sites and paths
{
"name": "my_sharepoint_connector",
"description": "My SharePoint connector for product data",
"is_indexable": true,
"connector": "sharepoint",
"connector_configuration": {
"is_document_owner": true,
"content_source_name": "SharePoint Files",
"access_credentials": {
"client_id": "my_client_id",
"client_secret": "my_client_secret",
"tenant_id": "my_tenant_id"
},
"logo_url": "https://mycompany.com/logo.png",
"include_sub_sites": true,
"drive_inclusion_regex_patterns": [
"ZetaDrive/.*"
],
"site_exclusion_regex_patterns": [
"Zeta Private Team"
],
"path_inclusion_regex_patterns": [
"ZetaFiles/.*\\.docx$",
"ZetaFiles/.*\\.xlsx$"
],
"field_mappings": [
...
]
}
}
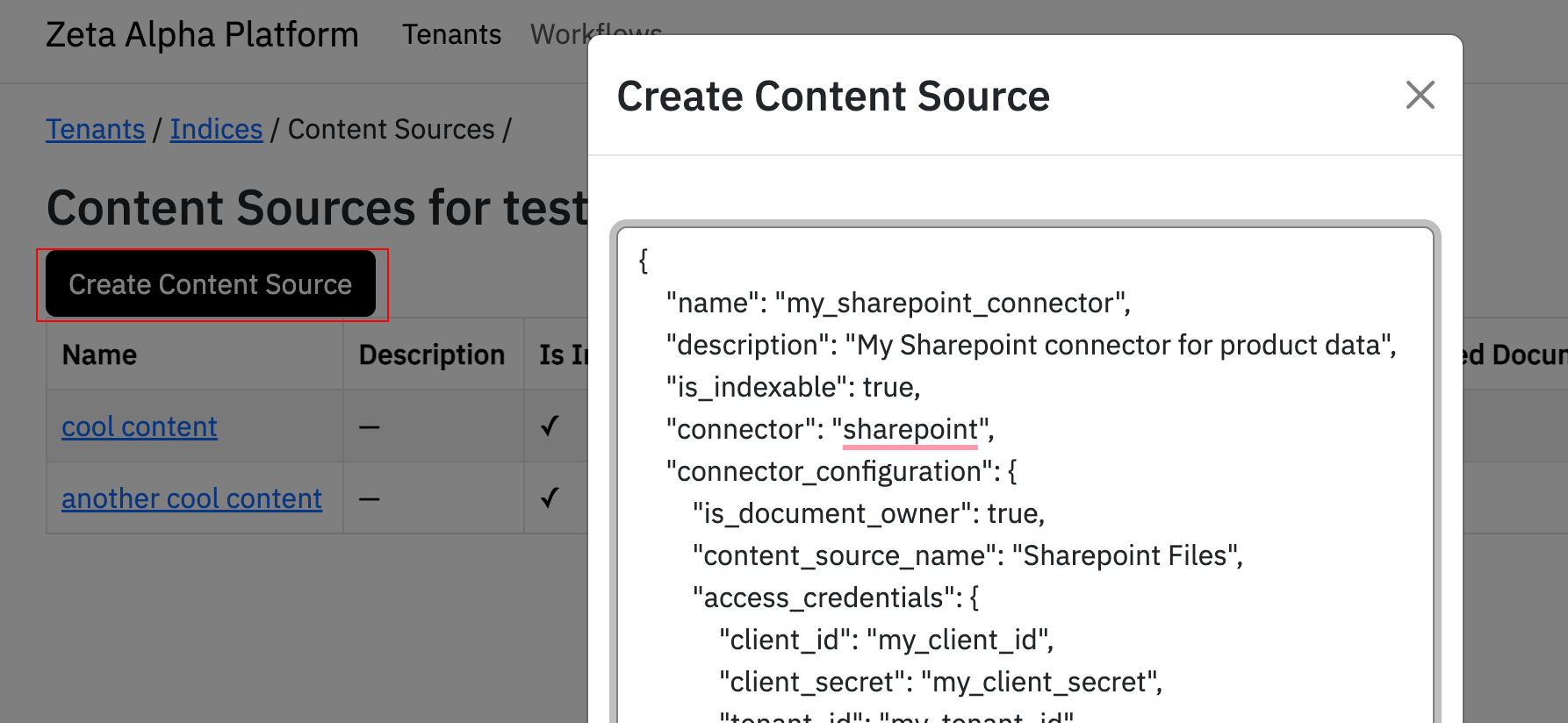
Step 4: Create the SharePoint Connector
To create your SharePoint connector in the Zeta Alpha Platform UI:
- Navigate to your tenant and click View next to your target index
- Click View under Content Sources for the index
- Click Create Content Source
- Paste your JSON configuration
- Click Submit
Crawling Behavior
The first time the connector runs, it crawls all information specified in the connector configuration.
After the initial crawl, only new, deleted, and modified documents will be crawled for the specified sites, drives, and paths. This incremental approach avoids crawling unnecessary data and improves performance.