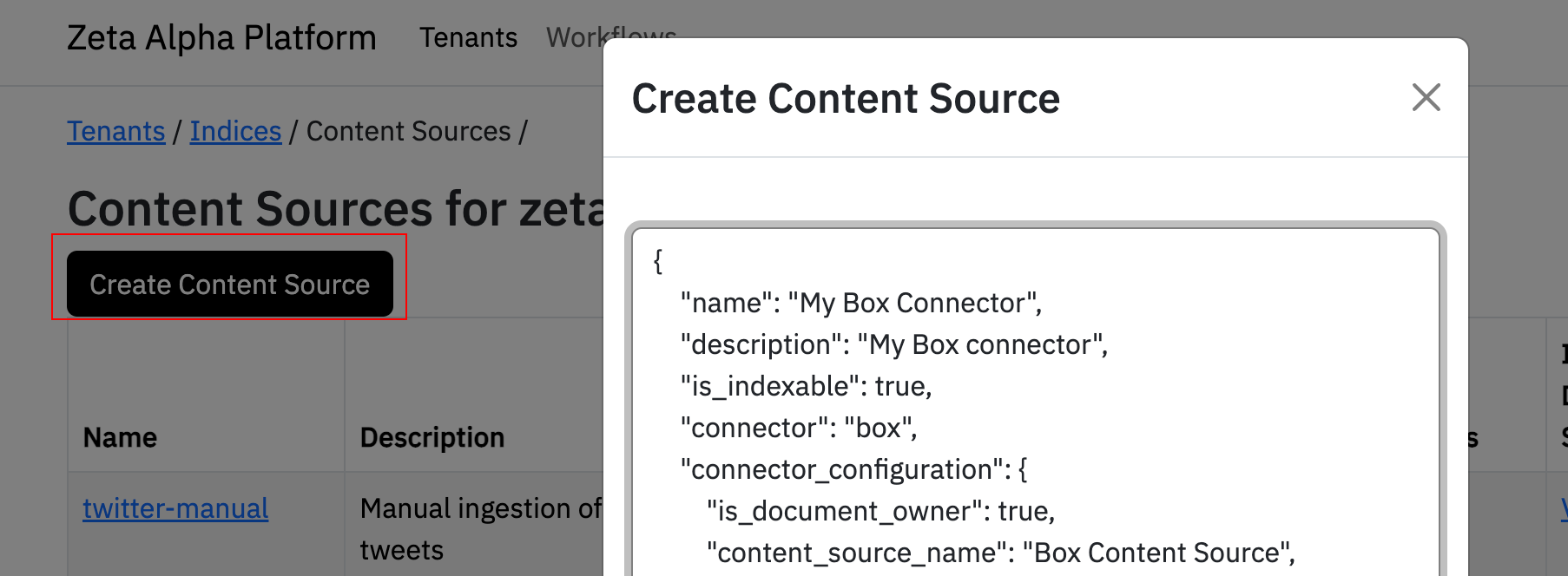
Create a Box Connector
A Box connector enables you to ingest data from your Box instance into the Zeta Alpha platform. This guide shows you how to create and configure a Box connector for your data ingestion workflows, including options that impact crawling performance.
Info: This guide presents an example configuration for a Box connector. For a complete set of configuration options, see the Box Connector Configuration Reference.
Prerequisites
Before you begin, ensure you have:
- Access to the Zeta Alpha Platform UI
- A tenant created
- An index created
- Box credentials (refer to the PDF tutorial "Connecting Box to Zeta Alpha.pdf" for detailed instructions)
Step 1: Create the Box Basic Configuration
To create a Box connector, define a configuration file with the following basic fields:
is_document_owner: (boolean) Indicates whether this connector "owns" the crawled documents. When set totrue, other connectors cannot crawl the same documents.content_source_name: (string) The name that identifies the content source in the UI.access_credentials: (object) The credentials required to access Box:client_id: The client ID of your Box applicationclient_secret: The client secret of your Box applicationenterprise_id: The enterprise ID of your Box account
logo_url: (string, optional) The URL of a logo to display on document cards
Example Configuration
{
"name": "My Box Connector",
"description": "My Box connector",
"is_indexable": true,
"connector": "box",
"connector_configuration": {
"is_document_owner": true,
"content_source_name": "Box Content Source",
"access_credentials": {
"client_id": "your-client-id",
"client_secret": "your-client-secret",
"enterprise_id": "your-enterprise-id"
},
"logo_url": "https://example.com/logo.png"
...
}
}
Step 2: Add Field Mapping Configuration
When crawling Box, the connector extracts document metadata and content as described in the Box Connector Configuration Reference. You can map these Box fields to your index fields using the field_mappings configuration.
Example Field Mappings
The following example shows field mappings for the default index fields:
{
...
"connector_configuration": {
...
"field_mappings": [
{
"content_source_field_name": "name",
"index_field_name": "DCMI.title"
},
{
"content_source_field_name": "description",
"index_field_name": "DCMI.abstract"
},
{
"content_source_field_name": "owner",
"index_field_name": "DCMI.creator",
"inner_field_mappings": [
{
"content_source_field_name": "display_name",
"index_field_name": "full_name"
}
]
},
{
"content_source_field_name": "content_source_name",
"index_field_name": "DCMI.source"
},
{
"content_source_field_name": "created_at",
"index_field_name": "DCMI.created"
},
{
"content_source_field_name": "file_id",
"index_field_name": "DCMI.identifier"
},
{
"content_source_field_name": "uri",
"index_field_name": "uri"
},
{
"content_source_field_name": "uri_hash",
"index_field_name": "uri_hash"
},
{
"content_source_field_name": "document_content_type",
"index_field_name": "document_content_type"
},
{
"content_source_field_name": "document_content",
"index_field_name": "document_content"
},
{
"content_source_field_name": "document_content_path",
"index_field_name": "document_content_path"
}
],
...
}
}
Step 3: Specify What to Crawl
You can configure the Box connector to crawl specific content using the following options:
path_inclusion_regex_patterns: (array of strings, optional) Regular expressions to match file paths for inclusion. Only files whose paths match these patterns will be crawled. If a file matches both inclusion and exclusion patterns, the exclusion takes precedence.path_exclusion_regex_patterns: (array of strings, optional) Regular expressions to match file paths for exclusion. Files whose paths match these patterns will not be crawled.since_crawl_date: (string, optional) Only crawl files updated after this date and time (ISO 8601 format).crawl_limit: (integer, optional) The maximum number of files to crawl in a single run.full_crawl: (boolean, optional, default:false) Whether to perform a full crawl of all files in the Box account.folder_ids: (array of strings, optional) The IDs of specific folders to crawl. If not specified, the connector crawls all accessible files. To find a folder ID, view the folder in the Box web app and extract the numeric identifier from the URL.
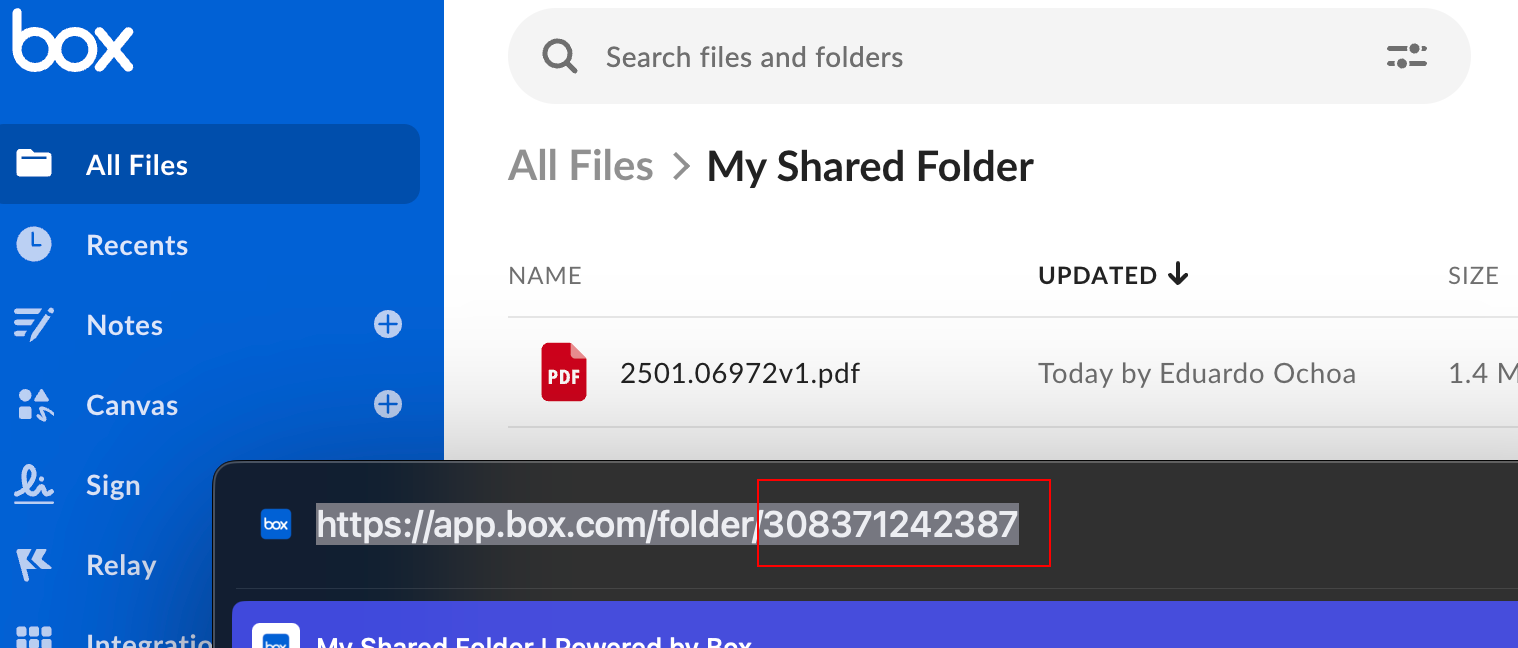
Example Configuration
{
...
"connector_configuration": {
...
"path_inclusion_regex_patterns": [
".*\\.pdf$",
".*\\.docx$"
],
"path_exclusion_regex_patterns": [
".*\\.txt$"
],
"folder_ids": [
"1234567890",
"0987654321"
],
"since_crawl_date": "2022-01-01T00:00:00Z",
"crawl_limit": 1000,
"full_crawl": false,
...
}
}
Step 4: Create the Box Content Source
To create your Box connector in the Zeta Alpha Platform UI:
- Navigate to your tenant and click View next to your target index
- Click View under Content Sources for the index
- Click Create Content Source
- Paste your JSON configuration
- Click Submit