Create a SharePoint Connector
A SharePoint connector enables you to ingest data from your SharePoint instance (and OneDrive) into the Zeta Alpha platform. This guide shows you how to create and configure a SharePoint connector for your data ingestion workflows, including options that impact crawling performance.
Info: This guide presents an example configuration for a SharePoint connector. For a complete set of configuration options, see the SharePoint Connector Configuration Reference.
Prerequisites
Before you begin, ensure you have:
- Access to the Zeta Alpha Platform UI
- A tenant created
- An index created
- Microsoft App (SharePoint/OneDrive) credentials (refer to the tutorial Configure Microsoft App Access for detailed instructions)
Step 1: Create the SharePoint Basic Configuration
To create a SharePoint connector, define a configuration file with the following basic fields:
is_document_owner: (boolean) Indicates whether this connector "owns" the crawled documents. When set totrue, other connectors cannot crawl the same documents.schedule: (string, optional) The schedule to crawl the SharePoint instance (cron format).content_source_name: (string) The name that identifies the content source in the index.certificate_credentials: (object, optional) The application credentials for certificate-based authentication. This is the recommended method — it supports all connector features including incremental permission sync, private keys never leave your infrastructure, and certificates can be rotated without updating Azure AD:client_id: The client ID of your SharePoint applicationtenant_id: The tenant ID of your SharePoint applicationcertificate_private_key: The PEM-encoded private key of the certificatecertificate_thumbprint: (optional) The SHA-1 thumbprint of the certificate. Not required whencertificate_public_keyis provided, since MSAL computes it automatically. Only needed if you omit the public certificate.certificate_public_key: (optional) The PEM-encoded public certificate. Not required whencertificate_thumbprintis provided. Required when using Subject Name/Issuer (SNI) authentication.
access_credentials: (object, optional) The application credentials using a client secret. Discouraged — client secret authentication does not support incremental permission detection, requiring a full access rights crawl instead which is slower and uses more API requests:client_id: The client ID of your SharePoint applicationclient_secret: The client secret of your SharePoint applicationtenant_id: The tenant ID of your SharePoint application
public_access_credentials: (object, optional) The user credentials for username/password authentication. Highly discouraged — requires storing user passwords and the account must not have MFA enabled:username: The username for SharePoint accesspassword: The password for SharePoint accessclient_secret: The client secret of your SharePoint applicationtenant_id: The tenant ID of your SharePoint application
certificate_credentials: (object, optional) The application credentials for certificate-based authentication. This is more secure than client secrets and recommended for production environments:client_id: The client ID of your SharePoint applicationtenant_id: The tenant ID of your SharePoint applicationcertificate_private_key: The PEM-encoded private key of the certificatecertificate_thumbprint: (optional) The SHA-1 thumbprint of the certificate. Not required whencertificate_public_keyis provided, since MSAL computes it automatically. Only needed if you omit the public certificate.certificate_public_key: (optional) The PEM-encoded public certificate. Not required whencertificate_thumbprintis provided. Required when using Subject Name/Issuer (SNI) authentication.
logo_url: (string, optional) The URL of a logo to display on document cards when no image is extracted from the pipeline.custom_metadata: (object, optional) Static key-value pairs added to every ingested document. See Content Source Custom Metadata.
Note: You must provide exactly one of certificate_credentials (certificate-based, recommended), access_credentials (client secret, discouraged), or public_access_credentials (username/password, highly discouraged).
Example Configuration
Here is an example of a basic SharePoint connector configuration with certificate-based authentication (recommended):
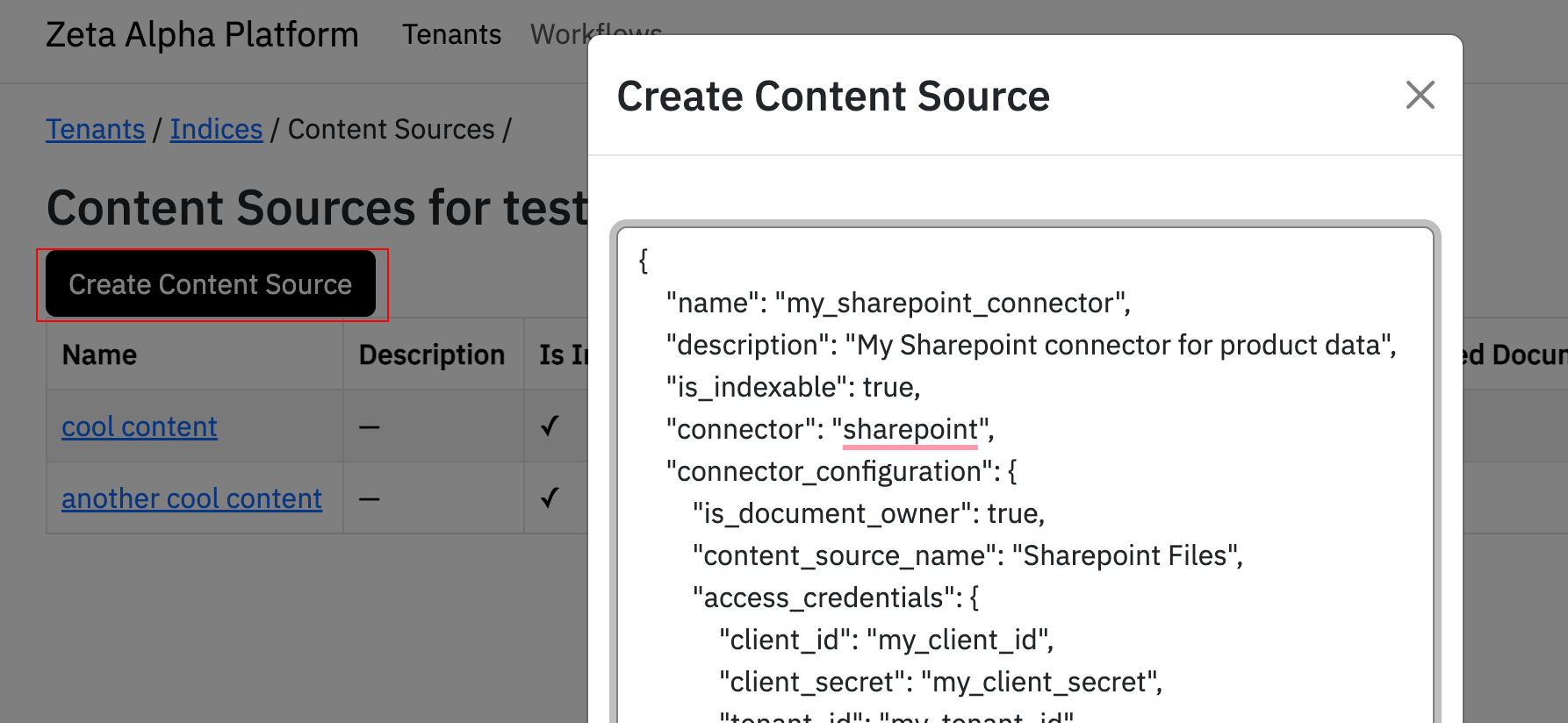
{
"name": "my_sharepoint_connector",
"description": "My SharePoint connector for product data",
"is_indexable": true,
"connector": "sharepoint",
"connector_configuration": {
"sharepoint": {
"is_document_owner": true,
"content_source_name": "SharePoint Files",
"certificate_credentials": {
"client_id": "my_client_id",
"tenant_id": "my_tenant_id",
"certificate_private_key": "-----BEGIN PRIVATE KEY-----\nMIIEv...\n-----END PRIVATE KEY-----",
"certificate_thumbprint": "AB12CD34EF56...",
"certificate_public_key": "-----BEGIN CERTIFICATE-----\nMIIC/j...\n-----END CERTIFICATE-----"
},
"logo_url": "https://mycompany.com/logo.png"
}
}
}
Alternatively, you can use client secret authentication with access_credentials, but this is discouraged because it does not support incremental permission detection. Permission updates require a full access rights crawl, which is slower and consumes more API requests:
{
"name": "my_sharepoint_connector",
"description": "My SharePoint connector for product data",
"is_indexable": true,
"connector": "sharepoint",
"connector_configuration": {
"sharepoint": {
"is_document_owner": true,
"content_source_name": "SharePoint Files",
"access_credentials": {
"client_id": "my_client_id",
"client_secret": "my_client_secret",
"tenant_id": "my_tenant_id"
},
"logo_url": "https://mycompany.com/logo.png"
}
}
}
You can also use username/password authentication with public_access_credentials, but this is highly discouraged:
{
"name": "my_sharepoint_connector",
"description": "My SharePoint connector for product data",
"is_indexable": true,
"connector": "sharepoint",
"connector_configuration": {
"sharepoint": {
"is_document_owner": true,
"content_source_name": "SharePoint Files",
"public_access_credentials": {
"username": "user@domain.com",
"password": "user_password",
"client_secret": "my_client_secret",
"tenant_id": "my_tenant_id"
},
"logo_url": "https://mycompany.com/logo.png"
}
}
}
Step 2: Add Field Mapping Configuration
When crawling SharePoint, the connector extracts document metadata and content as described in the SharePoint Connector Configuration Reference. You can map these SharePoint fields to your index fields using the field_mappings configuration.
Example Field Mappings
The following example shows field mappings for the default index fields:
{
...
"connector_configuration": {
"sharepoint": {
...
"field_mappings": [
{
"content_source_field_name": "name",
"index_field_name": "DCMI.title"
},
{
"content_source_field_name": "last_modified_date_time",
"index_field_name": "DCMI.modified"
},
{
"content_source_field_name": "created_date_time",
"index_field_name": "DCMI.created"
},
{
"content_source_field_name": "author",
"index_field_name": "DCMI.creator",
"inner_field_mappings": [
{
"content_source_field_name": "display_name",
"index_field_name": "full_name"
},
{
"content_source_field_name": "display_name",
"index_field_name": "Ontology_ID"
}
]
},
{
"content_source_field_name": "content_source_name",
"index_field_name": "DCMI.source"
}
],
...
}
...
}
}
Step 3: Specify What to Crawl
You can configure the SharePoint connector to crawl specific content from your SharePoint instance. While a full crawl is possible, we recommend specifying what to crawl to avoid unnecessary data and improve performance.
Available Configuration Options
include_one_drives: (boolean, optional) Whether to include OneDrives in the crawl.one_drive_users: (array of strings, optional) If OneDrives are included, specify the email addresses of users whose drives should be crawled.drive_ids: (array of strings, optional) Specific drive IDs to crawl. When provided, site discovery is skipped entirely and only the specified drives are crawled. Drive IDs can be obtained from the Microsoft Graph API.drive_inclusion_regex_patterns: (array of strings, optional) Regular expressions to match specific drives to crawl.drive_exclusion_regex_patterns: (array of strings, optional) Regular expressions to exclude specific drives from the crawl.site_paths: (array of objects, optional) Specific sites to crawl. If not specified, the connector crawls all sites. Each object contains:collection_hostname: The hostname of the SharePoint instancesite_relative_path: The relative path of the site to crawl
include_sub_sites: (boolean, optional) If nosite_pathsspecified, whether to include sub-sites in the crawl.site_inclusion_regex_patterns: (array of strings, optional) Regular expressions to match specific sites to crawl.site_exclusion_regex_patterns: (array of strings, optional) Regular expressions to exclude specific sites from the crawl.path_inclusion_regex_patterns: (array of strings, optional) Regular expressions to match specific file paths to crawl.path_exclusion_regex_patterns: (array of strings, optional) Regular expressions to exclude specific file paths from the crawl.allow_access_rights: (array of objects, optional) A list aditional access rights to grant to all documents crawled by this connector. Each object must contain:name: The name of the access right (e.g. group name or email)type: The type of access right (userorgroup)
deny_access_rights: (array of objects, optional) A list of access rights to deny to all documents crawled by this connector. Structure is the same asallow_access_rights.
Example Configurations
Example 1: Crawl all information in the SharePoint instance
{
"name": "my_sharepoint_connector",
"description": "My SharePoint connector for product data",
"is_indexable": true,
"connector": "sharepoint",
"connector_configuration": {
"sharepoint": {
"is_document_owner": true,
"content_source_name": "SharePoint Files",
"access_credentials": {
"client_id": "my_client_id",
"client_secret": "my_client_secret",
"tenant_id": "my_tenant_id"
},
"logo_url": "https://mycompany.com/logo.png",
"include_one_drives": true,
"one_drive_users": [
"zeta@zeta-alpha.com",
"alpha@zeta-alpha.com"
],
"field_mappings": [
...
]
}
}
}
Example 2: Crawl only specific sites and paths
{
"name": "my_sharepoint_connector",
"description": "My SharePoint connector for product data",
"is_indexable": true,
"connector": "sharepoint",
"connector_configuration": {
"sharepoint": {
"is_document_owner": true,
"content_source_name": "SharePoint Files",
"access_credentials": {
"client_id": "my_client_id",
"client_secret": "my_client_secret",
"tenant_id": "my_tenant_id"
},
"logo_url": "https://mycompany.com/logo.png",
"include_sub_sites": true,
"drive_inclusion_regex_patterns": [
"ZetaDrive/.*"
],
"site_exclusion_regex_patterns": [
"Zeta Private Team"
],
"path_inclusion_regex_patterns": [
"ZetaFiles/.*\\.docx$",
"ZetaFiles/.*\\.xlsx$"
],
"field_mappings": [
...
]
}
}
}
Step 4: Create the SharePoint Connector
To create your SharePoint connector in the Zeta Alpha Platform UI:
- Navigate to your tenant and click View next to your target index
- Click View under Content Sources for the index
- Click Create Content Source
- Paste your JSON configuration
- Click Submit
Crawling Behavior
The first time the connector runs, it crawls all information specified in the connector configuration.
After the initial crawl, only new, deleted, and modified documents will be crawled for the specified sites, drives, and paths. This incremental approach avoids crawling unnecessary data and improves performance.
Incremental Permission Sync
In addition to content changes, the connector also detects permission-only changes (e.g., when a user is granted or revoked access to a document without modifying the document itself). This uses the SharePoint REST getchanges API to track role assignment additions and removals.
Note: Incremental permission detection requires delegated authentication (certificate or ROPC credentials). Client secret authentication (app-only tokens) does not support the SharePoint
getchangesAPI and will skip incremental permission updates. Use the full access rights crawl as a workaround (see below).
Full Access Rights Crawl
You can configure the connector to perform a full access rights refresh without re-downloading content. This iterates all documents and emits updated permissions, then advances the access rights change token while leaving content tokens untouched.
This is useful for:
- Bulk-refreshing permissions at any point in time
- Working around the client secret limitation for incremental permission detection
- Recovering from a missed permission change window
To enable, set full_access_rights_crawl to true in the connector configuration:
{
"name": "my_sharepoint_connector",
"connector": "sharepoint",
"connector_configuration": {
"sharepoint": {
...
"full_access_rights_crawl": true
}
}
}
Since-Date Crawl
You can reseed delta crawling from a specific date by setting since_crawl_date (in YYYY-MM-DD format). When set, the connector ignores the stored delta tokens for that run and re-detects content and access-right changes modified on or after that date, then refreshes the tokens so subsequent runs resume incrementally.
This is useful for:
- Recovering from a missed change window
- Backfilling changes after expanding the crawl scope (e.g., adding new
site_pathsordrive_ids) - Catching up changes without paying for a full re-crawl
since_crawl_date is ignored when full_crawl is true.
{
"name": "my_sharepoint_connector",
"connector": "sharepoint",
"connector_configuration": {
"sharepoint": {
...
"since_crawl_date": "2024-01-15"
}
}
}
Crawl Mode Priority
When the connector runs, it selects the crawl mode in the following order:
- Full crawl — if
full_crawlis set totrue - Since-date crawl — if
since_crawl_dateis set - Full crawl — if this is the first run (no delta tokens stored)
- Full access rights crawl — if
full_access_rights_crawlis set totrue - Update crawl — incremental mode (default)
Authentication and Feature Compatibility
| Feature | Certificate | ROPC | Client Secret |
|---|---|---|---|
| Full crawl | ✅ | ✅ | ✅ |
| Incremental content changes | ✅ | ✅ | ✅ |
| Incremental permission changes | ✅ | ✅ | ❌ |
| Full access rights crawl | ✅ | ✅ | ✅ |
Scheduling with Task Types
A SharePoint source syncs along two dimensions — document content and access rights — and each runs as either a full pass or a delta pass. These map to four task types you can schedule independently:
content_full— crawl the configured scope in full: ingest new and changed documents, refresh metadata, and remove documents the source no longer has.content_delta— ingest only the documents that changed since the last content run (incremental crawl).access_rights_full— re-apply permissions to every document in scope, without re-downloading content (the Full Access Rights Crawl above).access_rights_delta— apply only the permission changes since the last access-rights run (the Incremental Permission Sync above).
See Task types for the authoritative definitions. SharePoint does not accept the enhancement_* task types — those belong to enhancement connectors.
Schedule each task on its own cadence. Set scheduled_tasks, a top-level list on the content source (alongside name and connector, not inside connector_configuration), with one { "task_type": ..., "schedule": "<cron>" } entry per task type:
{
"name": "my_sharepoint_connector",
"connector": "sharepoint",
"scheduled_tasks": [
{ "task_type": "content_delta", "schedule": "*/15 * * * *" },
{ "task_type": "access_rights_delta", "schedule": "*/15 * * * *" },
{ "task_type": "content_full", "schedule": "0 4 * * 0" }
],
"connector_configuration": {
"sharepoint": {
"...": "..."
}
}
}
Each task_type may appear at most once. Editing the list reconciles the schedules; an empty list clears them. A source runs on either the single schedule cron or scheduled_tasks — use scheduled_tasks (and leave schedule unset) when you want independent per-task cadences and full-crawl reconciliation. Per-task scheduling is configured through the content-source API or the platform-admin content-source editor (create / edit). See How a content source runs for the general scheduling model.
Delta runs capture only forward changes. Unlike the single-schedule crawl, which performs a full crawl on its first run (see Crawl Mode Priority), an explicitly scheduled content_delta does not backfill: its first run on a source with no prior delta state records the current position and ingests nothing, and from then on it ingests only what changed since the previous content run. content_full is the authoritative pass — it re-crawls the scope, refreshes metadata, and removes documents the source has dropped. If the connector's delta state expires on the SharePoint side, the next delta run re-anchors to the current position and the following content_full reconciles any skipped window. A periodic content_full is therefore what guarantees the index converges on the source.
Recommended lifecycle.
- Seed the delta first. Run
content_deltaonce before the initial full crawl. It is cheap — it only records the starting position — and arming the delta cursor first means edits made during the initial full crawl (which can take hours on a large source) are still picked up by the next delta run, closing the change-gap. - Run
content_fullonce to load and reconcile the full corpus. - Steady state. Schedule
content_deltaandaccess_rights_deltafrequently (for example every 15 minutes) for freshness, andcontent_fullon a slower cadence (for example weekly, off-peak) to reconcile — refreshing stale metadata and removing documents the source no longer has.
Fetch tuning (advanced). SharePoint downloads document bodies in parallel batches. Two optional base connector-configuration fields tune this: fetch_batch_size (documents per fetch, which is also the ingestion batch size) and fetch_concurrency (how many batches download at once). Leave them unset to use platform defaults; lower fetch_concurrency when the source shares a Microsoft Graph rate-limit budget with other connectors, or raise it to speed up large crawls.