Extract Metadata using AI Agents
You can extract metadata from document content using AI agents. This extracted information is considered an enhancement since the metadata is not part of the original document content.
This guide shows you how to configure a metadata extractor for your data ingestion workflows.
Note: The extracted information may override the metadata of the document in the index. The original metadata will still be visible in the "Ingested Documents" section, and any extracted data will be attached under the
enhancementssection of each document.
Prerequisites
Before you begin, ensure you have:
- Access to the Zeta Alpha Platform UI
- A tenant created
- An index created
Step 1: Define the Metadata Items to Extract
First, create a configuration that describes the metadata items to extract and their types. Each item is a configuration object containing the following fields:
field_name: (string) The name of the field to extract.field_type: (string) The type of the field to extract (use Python type hints notation).field_description: (string) A description of the field and instructions on how to extract it. This field is passed to the AI agent to guide extraction.
Example Metadata Items
[
{
"field_name": "title",
"field_type": "NotRequired[str]",
"field_description": "The title of the given document. If you cannot confidently determine the title, don't return this field."
},
{
"field_name": "authors",
"field_type": "NotRequired[List[Dict[str, str]]]",
"field_description": "List of authors associated with the paper. Each author is a dictionary with the following fields: name and affiliation."
},
{
"field_name": "summary",
"field_type": "NotRequired[str]",
"field_description": "Sometimes the summary is explicitly marked in the text, then extract it exactly without any paraphrasing. Otherwise, produce a summary that is about 10 sentences long. If you cannot confidently determine the summary, don't return this field."
},
{
"field_name": "date",
"field_type": "NotRequired[date]",
"field_description": "The publication date of the document. Ensure dates are not ambiguous and are in the format YYYY-MM-DD. If the date is ambiguous or in the future, do not return this field."
}
]
Step 2: Add the Agent to the Tenant Configuration
To add the agent to the tenant configuration, create a configuration that describes the agent and add it to the chat_bot_setups field of the tenant configuration. For complete configuration details, see the Tenant Configuration Reference.
The agent configuration contains the following fields:
bot_identifier: (string) The identifier of the agent.llm_configuration_name: (string) A reference to the LLM configuration in the tenant configuration.llm_tracing_configuration_name: (string, optional) A reference to the LLM tracing configuration.agent_name: (string) The name of the agent. Set it tometadata_extractororaffiliations_extractor.serving_url: (string) The URL of the agent serving endpoint.bot_configuration: (object) The configuration of the agent containing:agent_config: (object) Defines how the agent exchanges information with the Zeta Alpha platform:max_document_chars: (integer) The maximum number of characters of the document content that the agent will handle.max_response_tokens: (integer, optional) The maximum number of tokens that the agent will return.use_reflection_prompt: (boolean, optional) Whether the agent should check the output format to ensure correctness. This may slow down the agent and make an extra call.normalization_config: (array, optional, specific toaffiliations_extractor) List of fields and normalization functions to apply:field: The field to normalizenormalization_fn: The normalization function (currently onlyscientific_paperis supported, which normalizes affiliation names extracted from scientific papers)
cel_metadata_config: (object, optional, specific toaffiliations_extractor) Allows computing metadata fields deterministically using CEL (Common Expression Language) expressions evaluated against the document's existing metadata. This is useful for deriving structured fields from paths or identifiers without relying on the LLM. Contains:cel_map_literal: (object) A map of field names to CEL expressions. Each expression is evaluated against the document's existing metadata and the result is merged into the extracted metadata. Custom functions available:split(string, separator),slice(list, start, end),join(list, separator).
metadata_descriptions: (object) Contains the metadata items to extract:items: The list of items to extract (from Step 1)
Example Tenant Configuration
Here is an example tenant configuration for the metadata_extractor and affiliations_extractor agents:
{
...
"features": {
"chat_bot_setups": [
{
"bot_identifier": "metadata_extractor",
"llm_configuration_name": "name_of_the_llm_configuration",
"agent_name": "metadata_extractor",
"bot_configuration": {
"agent_config": {
"max_document_chars": 24000,
"max_response_tokens": 4096,
"use_reflection_prompt": true
},
"metadata_descriptions": {
"items": [
{
"field_name": "title",
"field_type": "NotRequired[str]",
"field_description": "The title of the given document. If you cannot confidently determine the title, don't return this field."
},
...
]
}
},
"serving_url": "http://chat-service.production:8080"
},
{
"bot_identifier": "affiliations_extractor",
"llm_configuration_name": "name_of_the_llm_configuration",
"agent_name": "affiliations_extractor",
"bot_configuration": {
"agent_config": {
"max_document_chars": 24000,
"max_response_tokens": 4096,
"use_reflection_prompt": true,
"normalization_config": [
{
"field": "affiliations",
"normalization_fn": "scientific_paper"
}
],
"cel_metadata_config": {
"cel_map_literal": {
"department": "metadata[\"department\"]",
"full_path": "join(split(metadata[\"path\"], \"/\"), \" > \")"
}
}
},
"metadata_descriptions": {
"items": [
{
"field_name": "affiliations",
"field_type": "NotRequired[str]",
"field_description": "The list of authors affiliations."
},
...
]
}
},
"serving_url": "http://chat-service.production:8080"
},
...
]
},
...
}
Step 3: Create a Metadata Enhancement Workflow
To extract metadata from documents during ingestion, you need to use the metadata extractor in the document workflow. The processor in the main document workflow will trigger an enhancement workflow. Since the document is already in the pipeline, the enhanced metadata will eventually be indexed by the main document workflow.
To avoid reprocessing the document with the enhancement workflow, ensure the following workflow exists:
{
"name": "enhance-metadata",
"steps": [
{
"next_services": [
"pipeline_source"
],
"service": "start"
}
],
"tasks": [
{
"name": "pipeline-source",
"processor_settings": {
"always_run": true,
"skip_deleted": false
}
}
]
}
This workflow should be set as the workflow override for the metadata enhancement content source in the next step.
Step 4: Create the Metadata Enhancement Content Source
To create the content source, define a configuration file containing the following fields:
connector: (string) The connector type. Set it tometadata_extractor_enhancement.name: (string) The name of the enhancement.description: (string) A description of the enhancement.is_indexable: (boolean) Whether the enhancement is indexable.workflow_name_overrides: (object) The workflow name overrides for the enhancement:ingest: The workflow name for the ingestion of the enhancement (set toenhance-metadata)reingest: The workflow name for the re-ingestion of the enhancement (set toenhance-metadata)
connector_configuration: (object) The configuration of the enhancement:metadata_extractor_enhancement: (object) The metadata extractor enhancement configuration:enhancement_id: (string) The identifier of the enhancement (set tometadata)extractor_backend: (string) The backend of the extractor (set toagent)extractor_backend_configuration: (object) The agent configuration:agent: (object) The agent configuration:agent_identifier: (string) The ID of the agent to use for metadata extraction (should match one of the agents configured in the tenant configuration, e.g.,metadata_extractor)
fields_to_extract: (array) The fields to extract from the document content:field_name: (string) The name of the field to extractfield_type: (string) The type of the field to extract
field_mappings: (array) The field mappings between extracted fields and index field names
Example Configuration
Here is an example metadata enhancement content source configuration:
{
"name": "Metadata Extractor Enhancement",
"description": "Metadata extractor enhancement for documents",
"is_indexable": true,
"connector": "metadata_extractor_enhancement",
"workflow_name_overrides": {
"ingest": "enhance-metadata",
"reingest": "enhance-metadata"
},
"connector_configuration": {
"metadata_extractor_enhancement": {
"enhancement_id": "metadata",
"extractor_backend": "agent",
"extractor_backend_configuration": {
"agent": {
"agent_identifier": "metadata_extractor"
}
},
"fields_to_extract": [
{
"field_name": "title",
"field_type": "NotRequired[str]"
},
{
"field_name": "authors",
"field_type": "NotRequired[List[str]]"
},
{
"field_name": "summary",
"field_type": "NotRequired[str]"
},
{
"field_name": "date",
"field_type": "NotRequired[date]"
}
],
"field_mappings": [
{
"content_source_field_name": "date",
"index_field_name": "DCMI.created"
},
{
"content_source_field_name": "summary",
"index_field_name": "DCMI.abstract"
},
{
"content_source_field_name": "title",
"index_field_name": "DCMI.title"
},
{
"content_source_field_name": "authors",
"index_field_name": "DCMI.creator",
"inner_field_mappings": [
{
"content_source_field_name": ".",
"index_field_name": "full_name"
}
]
}
]
}
}
}
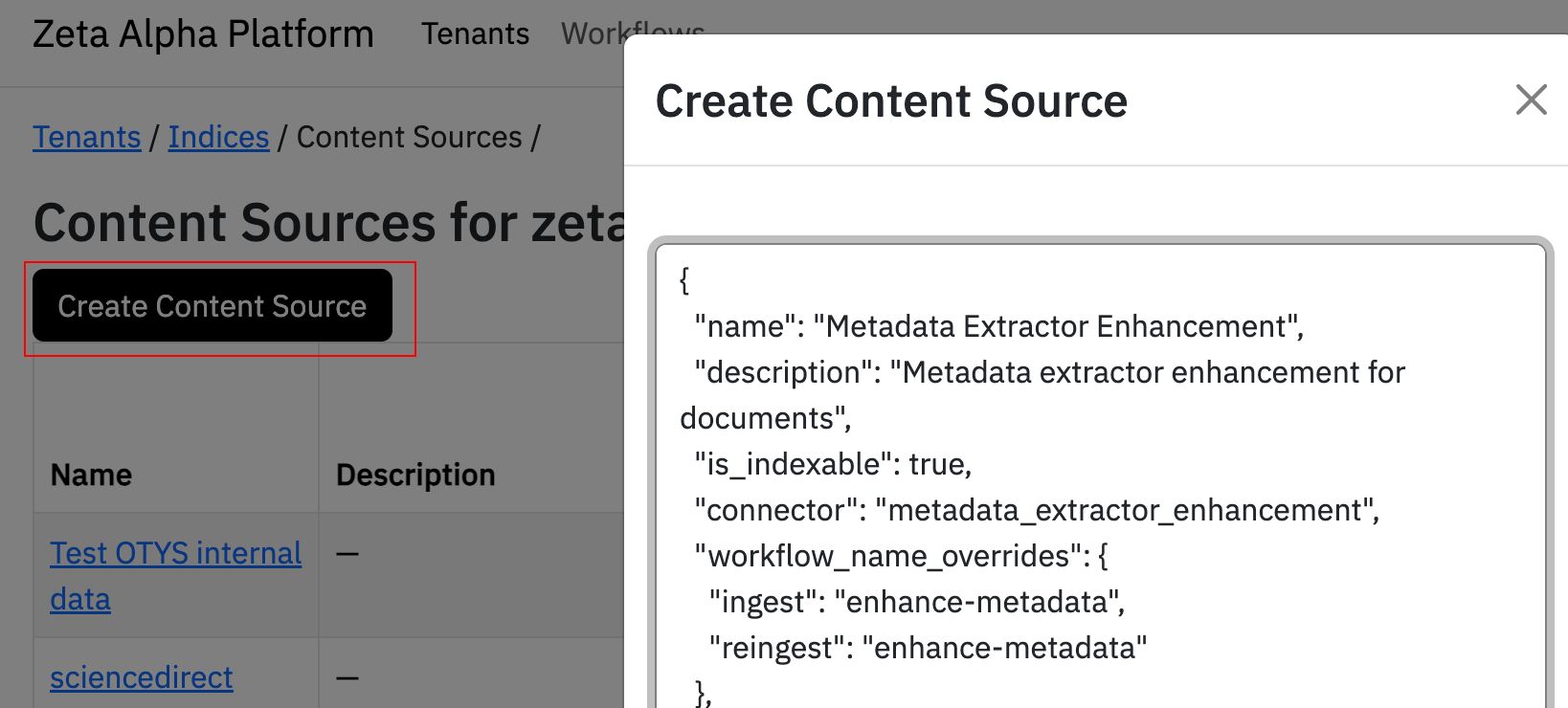
Create the Content Source
To create the metadata enhancement content source in the Zeta Alpha Platform UI:
- Navigate to your tenant and click View next to your target index
- Click View under Content Sources for the index
- Click Create Content Source
- Paste your JSON configuration
- Click Submit
Step 5: Add the Metadata Processor to the Documents Workflow
To extract information using the metadata enhancement, add the metadata processor to the documents workflow. This processor extracts information from document content according to the configuration described in the metadata enhancement content source.
Configuration Steps
- Identify the content source that ingests the documents from which you want to extract metadata
- Create or modify the workflow that content source uses by adding the
metadata_extractorprocessor - Ensure the processor is added after the text representation is created and before the
index_updaterprocessor - Add the following task to the list of workflow tasks:
{
"name": "metadata_extractor",
"local_settings": {
"default_ai_extraction": true,
"always_extract_metadata": true,
"preserved_fields": null
}
}
Configuration Parameters
-
always_extract_metadata: (boolean) When set totrue, always extracts metadata from document content, even when the document is reprocessed. Set tofalseto extract metadata only on first ingestion. -
preserved_fields: (array or null) Specifies which metadata fields should be protected from being overwritten during extraction. This optional parameter accepts:- A list of field names (using content source field names) that should be preserved if they already exist in the original document metadata
- A special wildcard value
["*"]which preserves all fields defined in the field mappings configuration nullto allow all fields to be overwritten
When a field is in the preserved_fields list, the metadata extractor will only extract and apply new values if the field is completely missing from the original metadata. This is particularly useful when certain metadata fields contain trusted data that should not be automatically replaced by AI-extracted values.
Step 6 (Optional): Extract Metadata from Existing Documents
To extract metadata from documents that have already been ingested, you need to reprocess them using a workflow that includes the metadata extractor and index updater processors.
Example Reprocessing Workflow
{
"name": "reprocess-metadata",
"steps": [
{
"next_services": [
"metadata_extractor"
],
"service": "start"
},
{
"next_services": [
"index_updater"
],
"service": "metadata_extractor"
},
{
"next_services": [
"pipeline_source"
],
"service": "index_updater"
}
],
"tasks": [
{
"name": "metadata_extractor",
"local_settings": {
"default_ai_extraction": true,
"always_extract_metadata": true
}
},
{
"name": "index_updater",
"processor_settings": {
"always_run": true,
"skip_deleted": false
}
},
{
"name": "pipeline_source",
"processor_settings": {
"always_run": true,
"skip_deleted": false
}
}
]
}
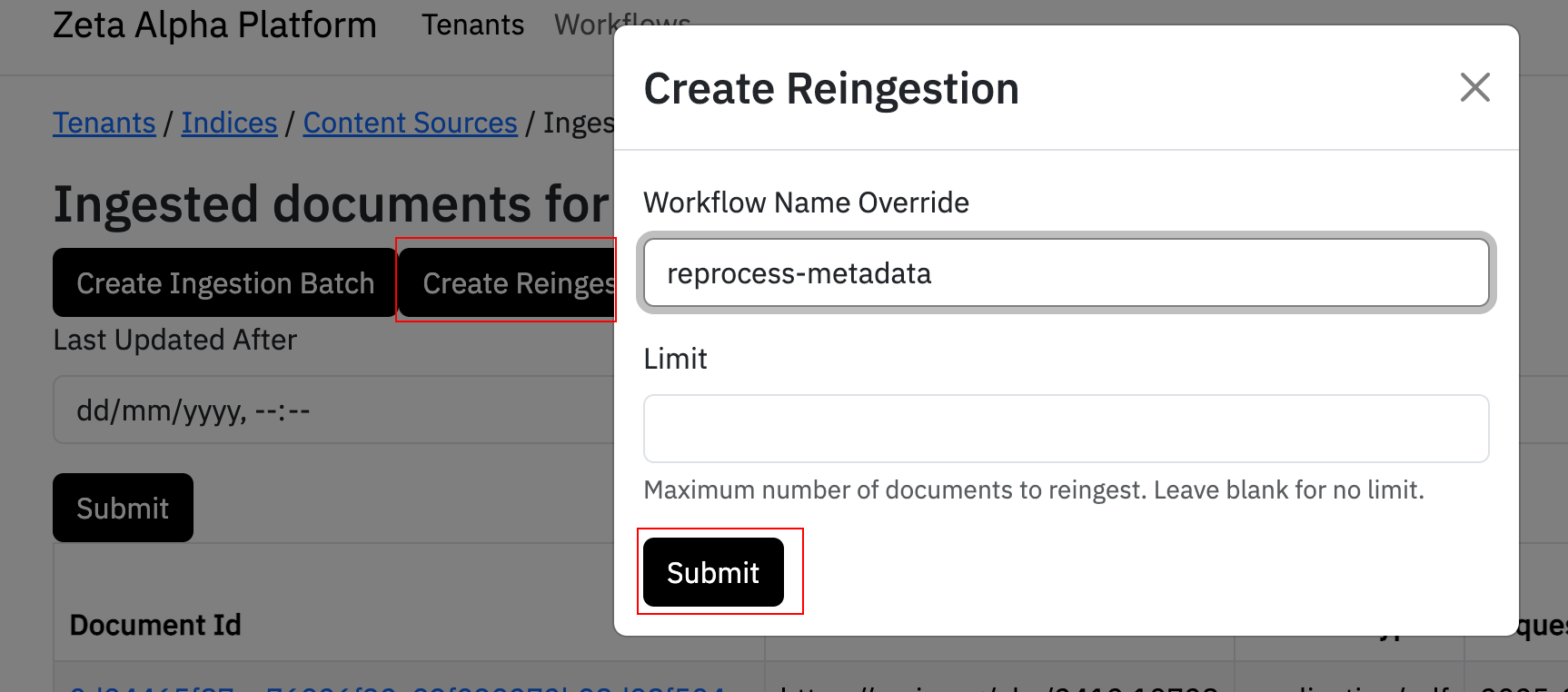
Trigger Reprocessing
To trigger reprocessing for a specific content source:
- Navigate to your tenant in the Zeta Alpha Platform UI and click View next to your target index
- Click View under Content Sources for the index
- Click View under Ingested Documents for the content source you want to reprocess
- Click Create Reingestion
- Enter the workflow name
reprocess-metadataunder the Workflow Name Override field - Click Submit