How to Evaluate Agent Quality Using RAGElo
In this guide, we will explore how to use the Evaluation interface in the UI to compare the quality of responses of different agents. The Evaluation interface provides a comprehensive evaluation process that includes collecting responses from multiple agents and evaluating their performance using the RAGElo tool.
Prerequisites
Before you begin, make sure you have completed the Getting Started with the Agents SDK tutorial and are familiar with How to Debug Agents Locally.
Overview of the Evaluation Interface
The Evaluation interface consists of three main tabs that guide you through the evaluation process:
- Debugging Tab: This is the main tab that allows you to interact with agents, override configurations, and select agents for evaluation.
- Collection Tab: This tab allows you to collect responses from multiple agents for a set of queries.
- Evaluation Tab: This tab allows you to evaluate the collected responses using RAGElo.
Debugging Tab
We already covered this tab in the How to Debug Agents Locally guide. Here we only focus on the Configuration Summary entry that each conversation includes. This entry has a toggle that allows you to add the agent and its configuration to the evaluation pool.
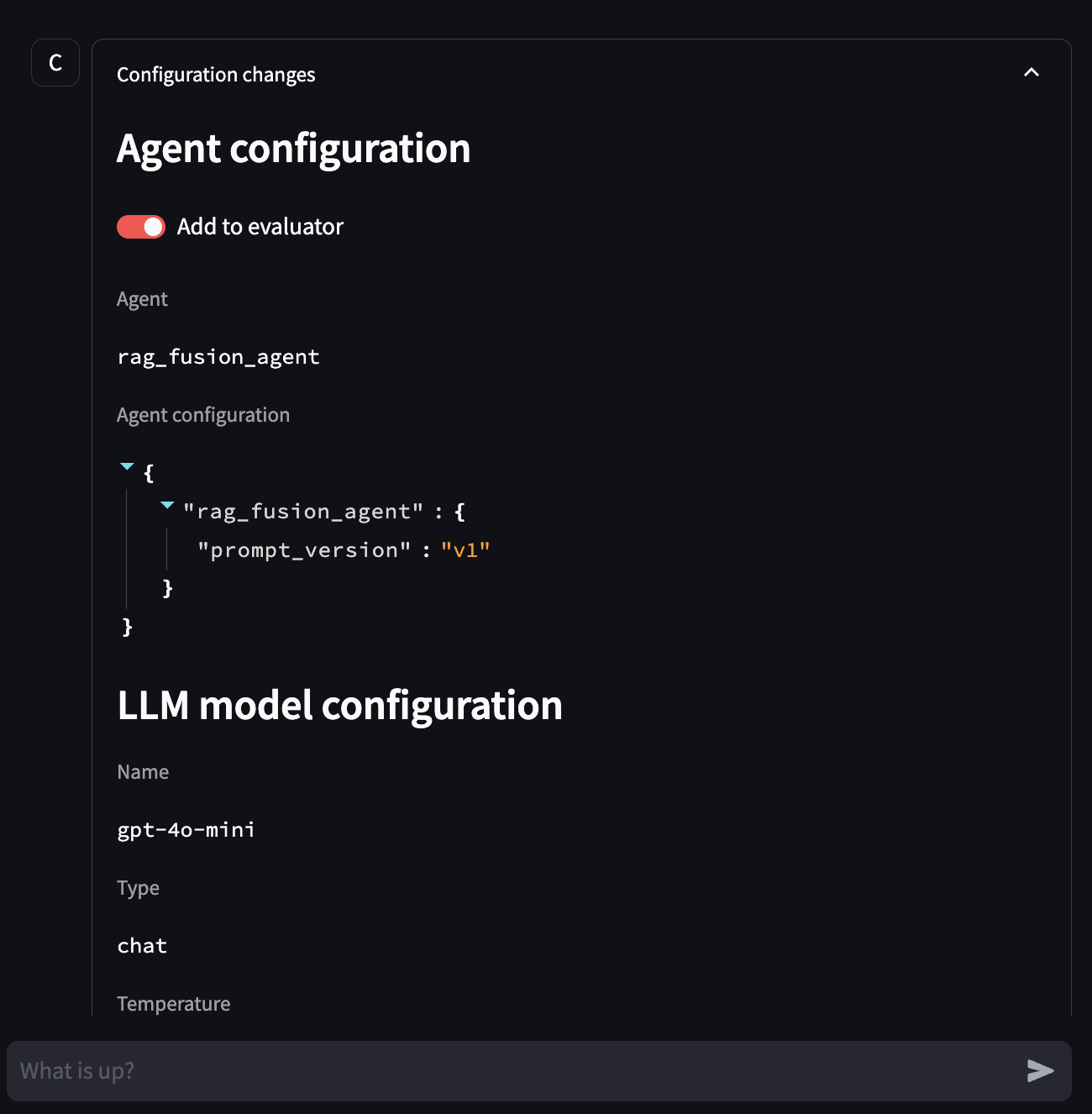
Image: The Configuration Summary entry with the toggle to add the agent to the evaluation pool.
You can use the historic conversation selector to review previous conversations and mark the agents you want to include in the evaluation pool.
Collection Tab
The Collection Tab is the second tab in the Evaluation interface. This tab allows you to collect responses from multiple agents for a set of queries.
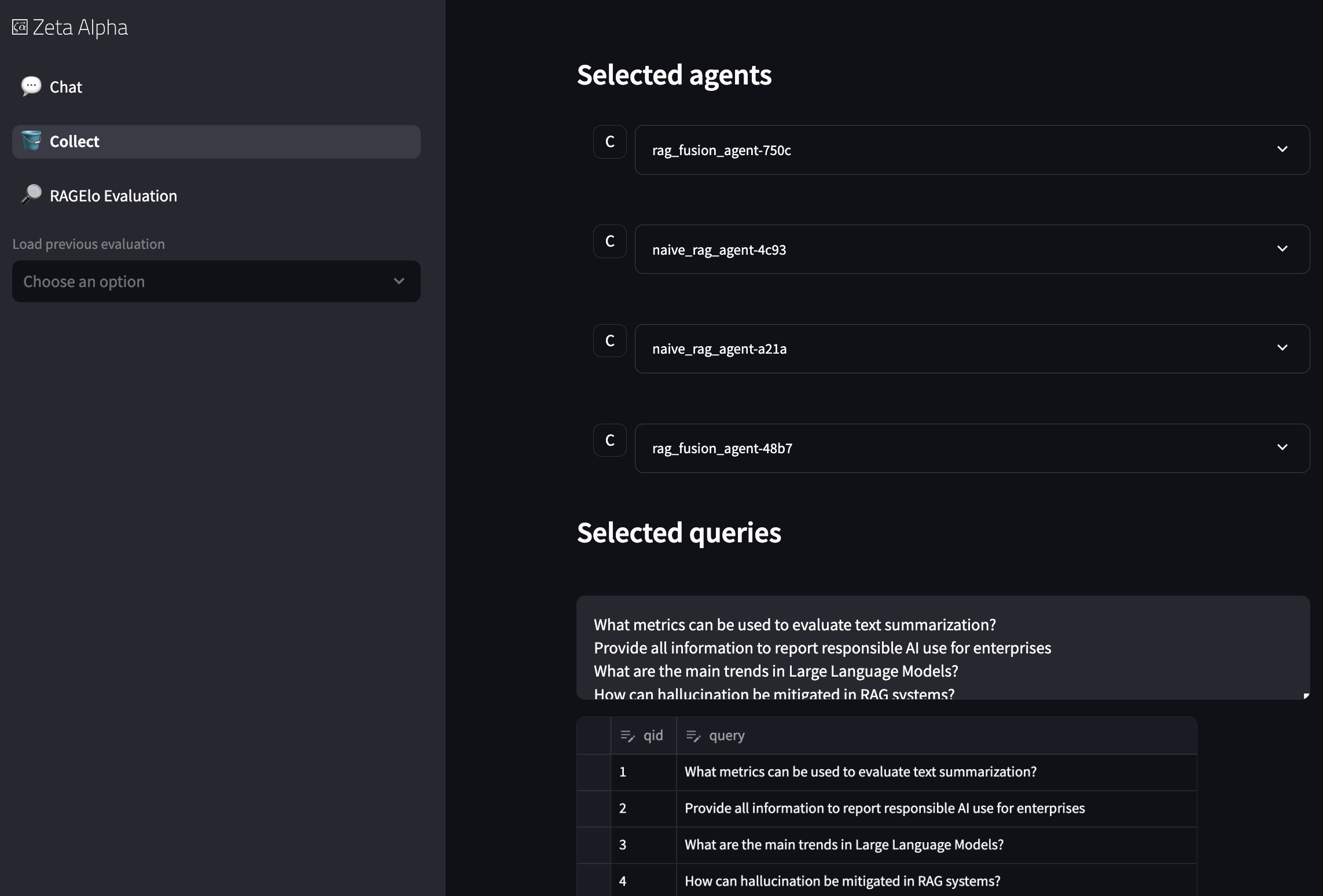
Image: The Collection Tab showing the list of selected agents and the query import options.
- Selected Agents: View the list of agents that have been added to the evaluation pool and review their configurations.
- Query Import: Import a list of queries that will be used to collect responses from the selected agents.
- Collect Button: Click the Collect button to run all the queries against all the selected agents and store the results.
When you click the Collect button, the system will run all the queries against all the selected agents and store the results in the configured storage backend.
Evaluation Tab
The Evaluation Tab is the third tab in the Evaluation interface. This tab allows you to evaluate the collected responses using the RAGElo algorithm.
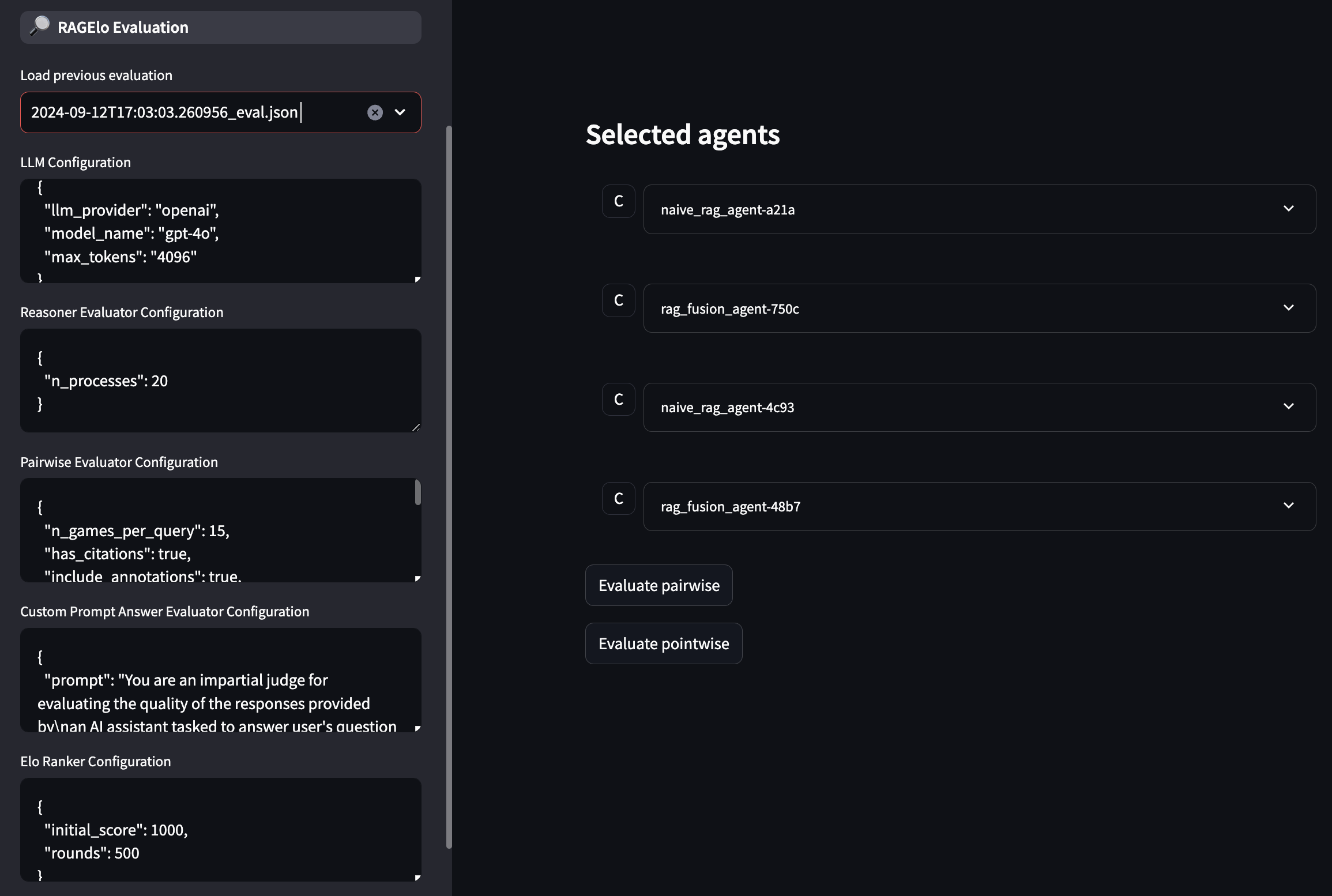
Image: The Evaluation Tab showing the evaluation configuration options and the selected agents.
- Collection Selector: Select the collection you wish to evaluate from the dropdown.
- RAGElo Configuration: Configure the RAGElo evaluation parameters.
- Evaluate Button: Click the Evaluate button to start the evaluation process.
When you click the Evaluate button, the system will create a tournament of matches between agents. A match is where the answers of a pair of agents are compared for a particular query. The winner of the match increases its score while the loser decreases it, following the ELO rating system. The way the winner is determined is based on the reasoning of the LLM-as-a-judge. This LLM-as-a-judge takes into consideration the cited references that the agents provide in their responses (if any), as well as the relevance of each reference with respect to the query. The LLM-as-a-judge then looks at both agents' responses and gives an extensive reasoning for picking the winner.
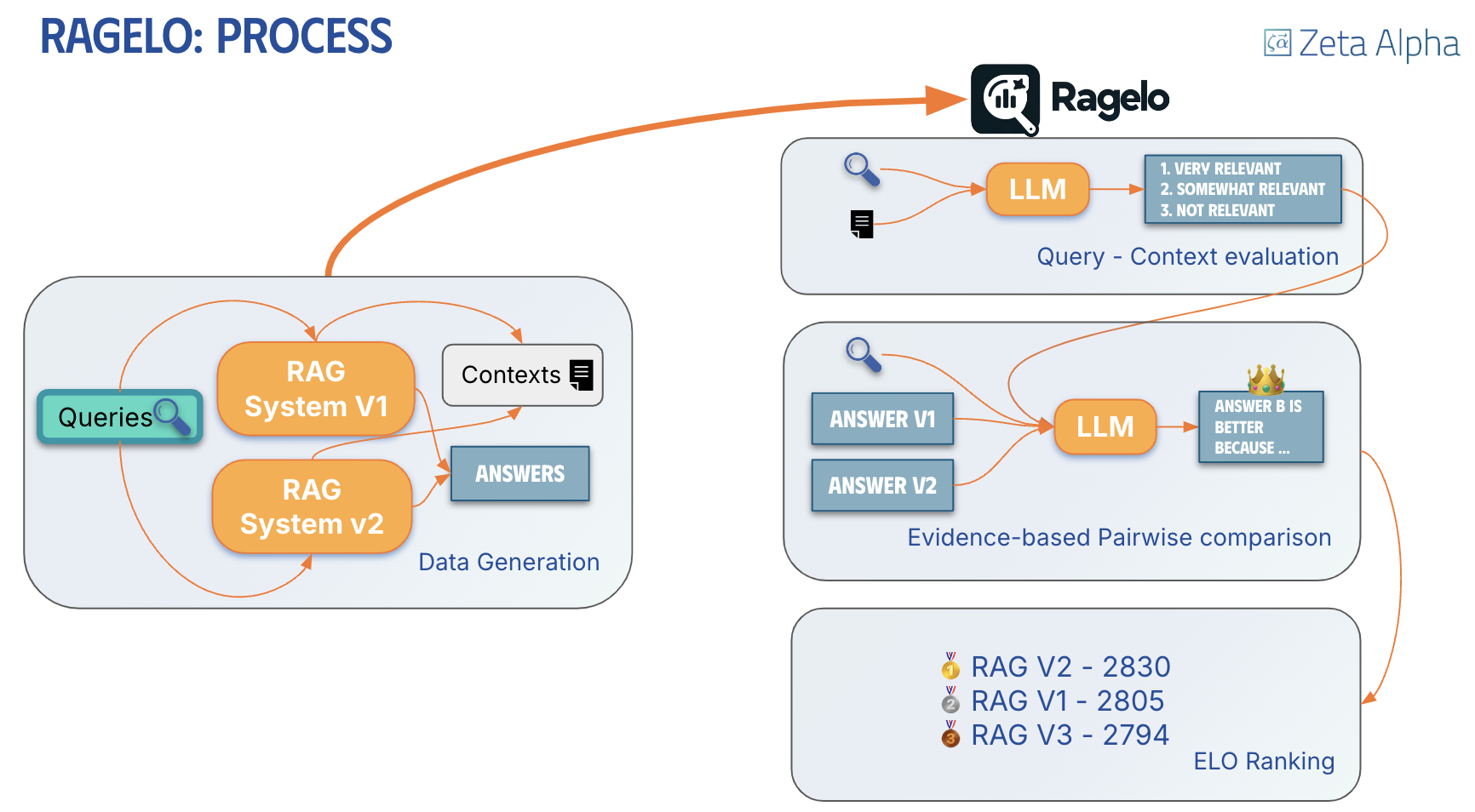
Evaluation Results
The evaluation results are displayed in a ranked table, where the agent with the highest rating is the best one according to the configuration parameters from the left panel.
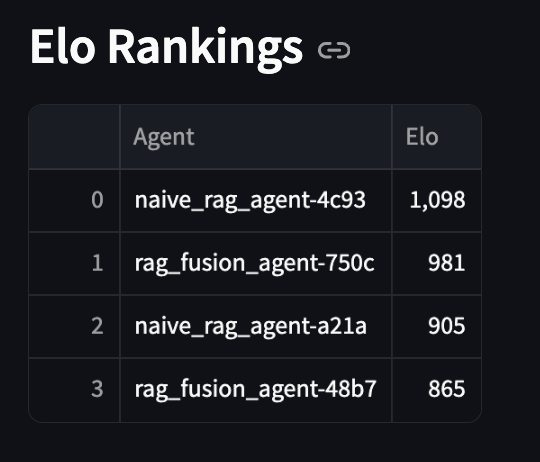
Image: The Evaluation Results Table showing the ranked list of agents.
Below the table, you can explore all the matches for each query. You can click on each match and read the reasoning of the LLM-as-a-judge for picking the winner.
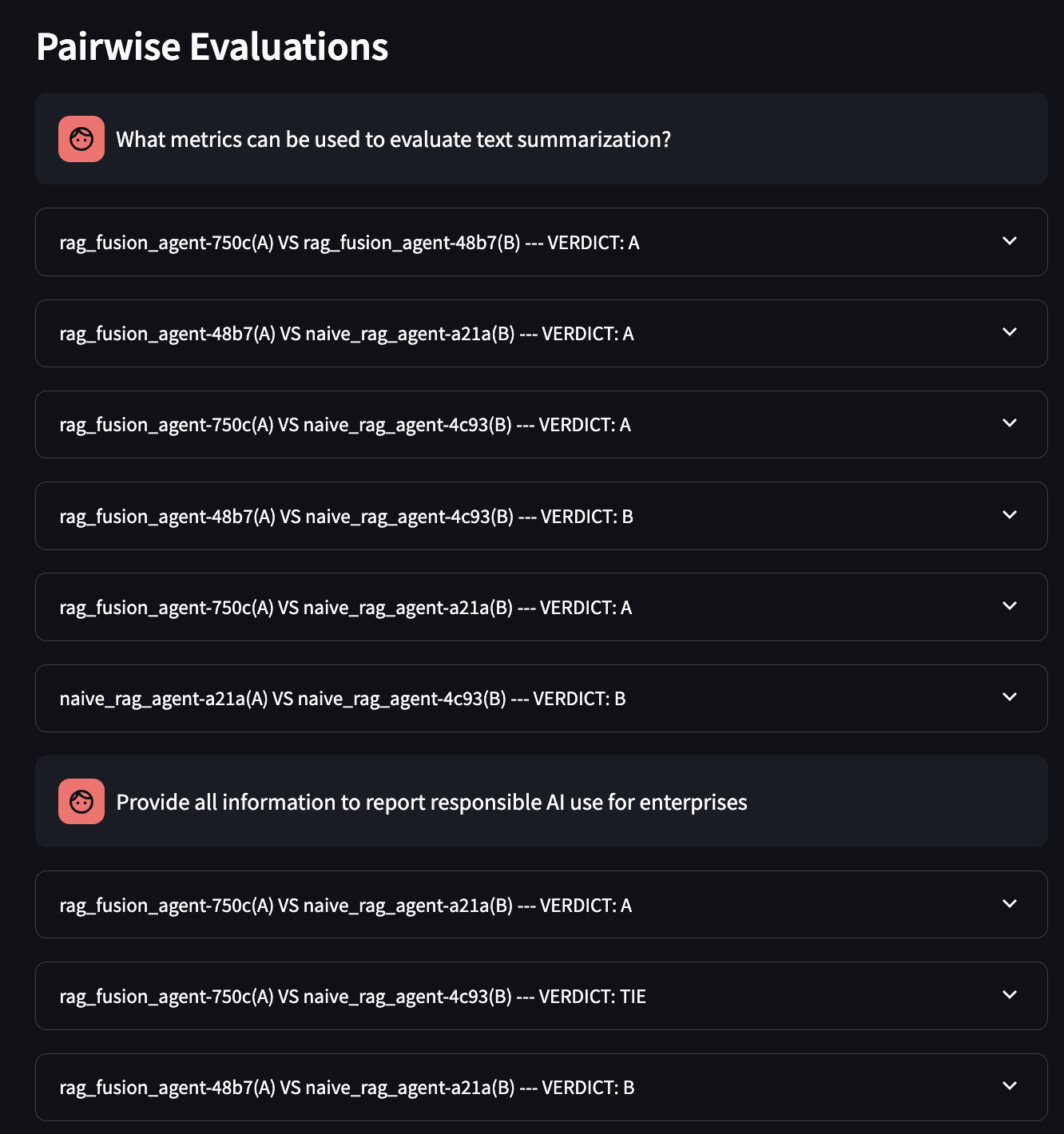
Image: The Match Details showing the reasoning of the LLM-as-a-judge for picking the winner.

Image: Zooming in on the reasoning of the LLM-as-a-judge for picking the winner.
Keep in mind that the LLM-as-a-judge is not perfect and will make mistakes. However, what we see is that when going through many matches, the ranking of the agents is quite consistent with the human judgment. For more information, checkout this talk on the RAGElo evaluation methodology: